Model Development and Training
Model Development and Training -

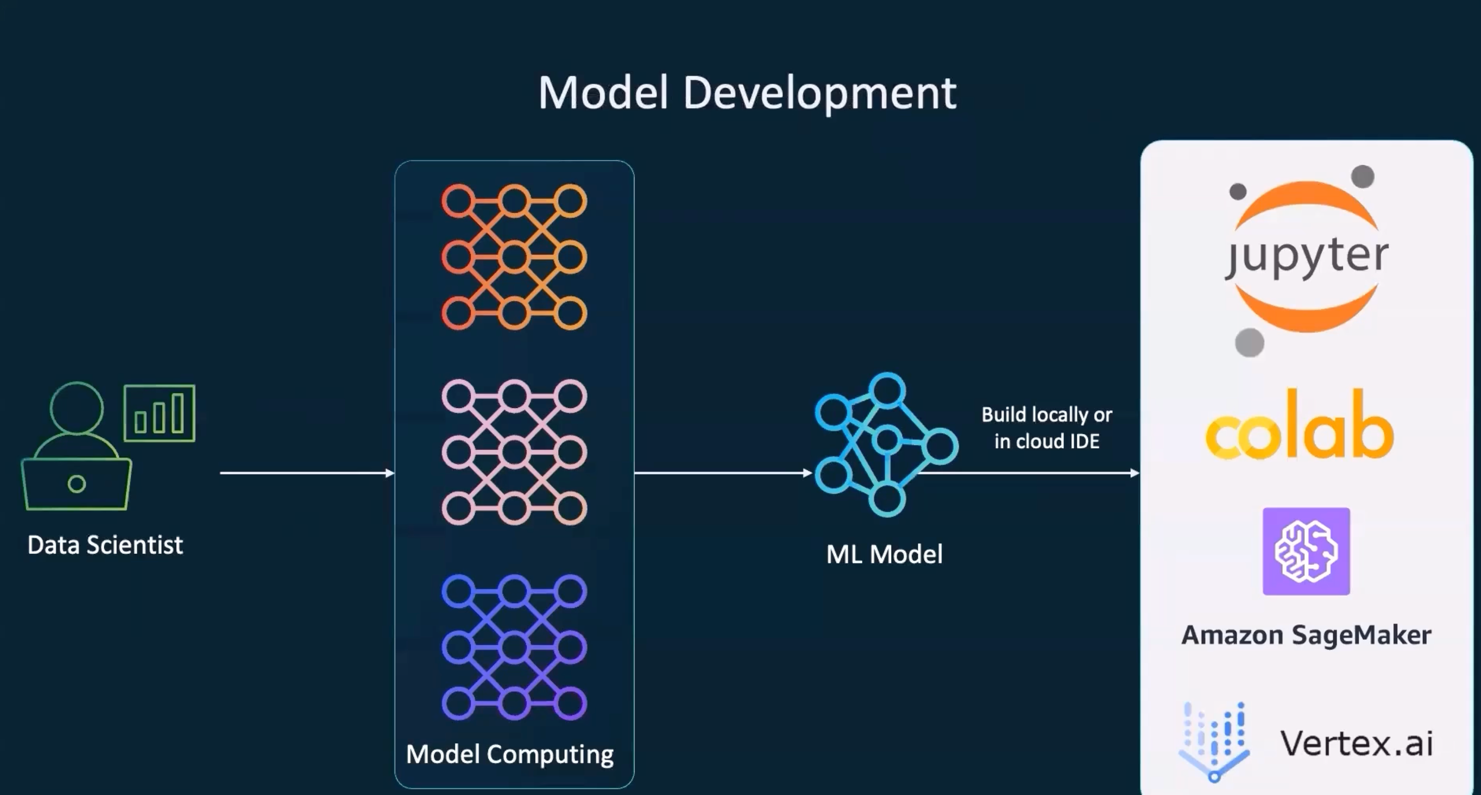
Model Development Tools -
Model Training & Hyperparameter Tuning
1Steps involving in training a machine-learning model and optimizing its performance...
2
3
4Once model is ready need to measure the metrics -
5 1. Precision - Correctly Predicted Positive Instances/Total Predicted Positives
6 2. Recall - Correctly Predicted Positive Instances/Total Actual Positives
7
8
9Model Traning with a larger dataset - Hyperparameter Tuning for iterative model improvement.
10
11
121. Train Model with the larger dataset.
132. Evaluate Precision and Recall at each stage.
143. Training data partitioning - Split -- 70% Training, 15% Validation, 15% Testing.
154. Hyperparameter Optimization(Grid Search)
165. Cross-Validation(5-Fold Cross Validation)
176. Performance Evaluation(85% Accuracy - F1-Score:0.80)
CPUs vs GPUs Comparison
1GPUs are needed for vector operations
CPU vs GPU -

MLflow Development Lifecycle -
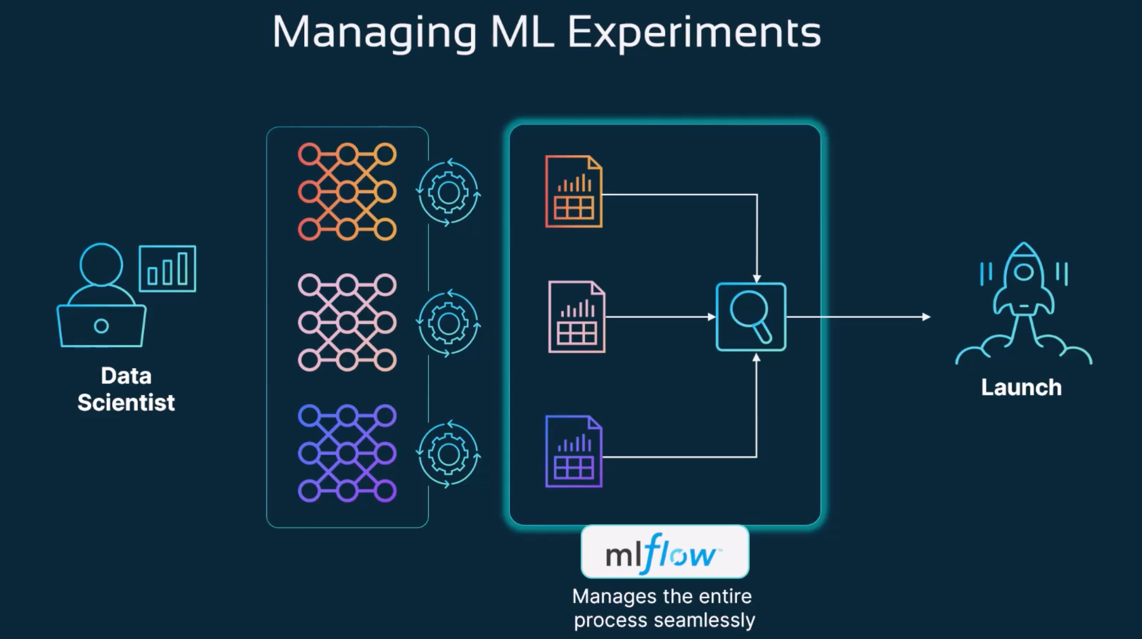
MLFlow Intro
1mlflow - Managing ML experiments
2
3
41. Model Selection - (Select from different machine learning models)
52. Run experiments on the selected models
63. Test the same-data with different ML Models
7
8The important step is visualizing the data and trying to understand which model is the best fit for this usecase.
9This is an iterative process - and this is where MLflow is actually helpful.
10
11mlflow is an open-source platform for managing the machine learning lifecycle, from tracking experiments to model deployment.
12
13MLFlow modules
14--------------------->
151. Tracking - Record and query experiments(code, data, config, results).
162. Projects - Packaging format for reproducible runs on any platform.
173. Models - General format that standardizes the deployment paths.
18 Once we have finalized the model, we can save it in MLflows format and deploy it in any format, whether it is flask, fastapi or BentoML
194. Model Registry - Centralized and collaborative model lifecycle management.
Install MLflow
1mlflow is an opensource platform for the complete machine-learning lifecycle.
2
3pip install mlflow
4
5(.venv) bharathkumardasaraju@4.Mode-Development-and-Training$ mlflow ui --port 5001
6[2025-03-04 21:05:55 +0800] [94896] [INFO] Starting gunicorn 23.0.0
7[2025-03-04 21:05:55 +0800] [94896] [INFO] Listening at: http://127.0.0.1:5001 (94896)
8[2025-03-04 21:05:55 +0800] [94896] [INFO] Using worker: sync
9[2025-03-04 21:05:55 +0800] [94897] [INFO] Booting worker with pid: 94897
10[2025-03-04 21:05:55 +0800] [94898] [INFO] Booting worker with pid: 94898
11[2025-03-04 21:05:55 +0800] [94899] [INFO] Booting worker with pid: 94899
12[2025-03-04 21:05:55 +0800] [94900] [INFO] Booting worker with pid: 94900
MLflow UI -
MLflow UI Supports Multiple Models -
MLflow Log - Langchain
1import mlflow
2from langchain_openai import OpenAI
3from langchain_core.prompts import PromptTemplate
4
5mlflow.set_experiment(experiment_id="0")
6mlflow.langchain.autolog()
7
8# Ensure that the "OPENAI_API_KEY" environment variable is set
9llm = OpenAI()
10prompt = PromptTemplate.from_template("Answer the following question: {question}")
11chain = prompt | llm
12
13# Invoking the chain will cause a trace to be logged
14chain.invoke("What is MLflow?")
MLflow Log - LlamaIndex
1import mlflow
2from llama_index.core import Document, VectorStoreIndex
3
4mlflow.set_experiment(experiment_id="0")
5mlflow.llama_index.autolog()
6
7# Ensure that the "OPENAI_API_KEY" environment variable is set
8index = VectorStoreIndex.from_documents([Document.example()])
9query_engine = index.as_query_engine()
10
11# Querying the engine will cause a trace to be logged
12query_engine.query("What is LlamaIndex?")
MLflow Log - AutoGen
1import os
2import mlflow
3from autogen import AssistantAgent, UserProxyAgent
4
5mlflow.set_experiment(experiment_id="0")
6mlflow.autogen.autolog()
7
8# Ensure that the "OPENAI_API_KEY" environment variable is set
9llm_config = {"model": "gpt-4o-mini", "api_key": os.environ["OPENAI_API_KEY"]}
10assistant = AssistantAgent("assistant", llm_config=llm_config)
11user_proxy = UserProxyAgent("user_proxy", code_execution_config=False)
12
13# All intermediate executions within the chat session will be logged
14user_proxy.initiate_chat(assistant, message="What is MLflow?", max_turns=1)
MLflow Log - OpenAPI
1import mlflow
2from openai import OpenAI
3
4mlflow.set_experiment(experiment_id="0")
5mlflow.openai.autolog()
6
7# Ensure that the "OPENAI_API_KEY" environment variable is set
8client = OpenAI()
9
10messages = [
11 {"role": "system", "content": "You are a helpful assistant."},
12 {"role": "user", "content": "Hello!"}
13]
14
15# Inputs and outputs of the API request will be logged in a trace
16client.chat.completions.create(model="gpt-4o-mini", messages=messages)
MLflow Log - Custom App
1import mlflow
2
3mlflow.set_experiment(experiment_id="0")
4
5@mlflow.trace
6def foo(a):
7 return a + bar(a)
8
9# Various attributes can be passed to the decorator
10# to modify the information contained in the span
11@mlflow.trace(name="custom_name", attributes={"key": "value"})
12def bar(b):
13 return b + 1
14
15# Invoking the traced function will cause a trace to be logged
16foo(1)
Model Development and Training -
MLflow Setup Demo
1Model development and Training
2
3MLflow
4
5Jupyter Notebook
6Colab Notebook
7Amazon SageMaker
8GCP Vertex.ai
9
10
11Build ML model - Train it and - Test it.
12
13mlflow ui --host 0.0.0.0
MLflow Example Demo -
Requirements
1mlflow
2scikit-learn
Validation Script
1from mlflow.tracking import MlflowClient
2
3client = MlflowClient()
4for rm in client.search_registered_models():
5 print(f"Model name: {rm.name}")
Example MLflow Python Script
1import mlflow
2import mlflow.sklearn
3from sklearn.datasets import make_regression
4from sklearn.model_selection import train_test_split
5from sklearn.linear_model import LinearRegression
6from sklearn.tree import DecisionTreeRegressor
7from sklearn.ensemble import RandomForestRegressor
8from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error, explained_variance_score
9import numpy as np
10
11# Set the MLflow tracking URI to the remote MLflow server
12mlflow.set_tracking_uri("http://localhost:5001")
13
14# Create synthetic data for regression
15X, y = make_regression(n_samples=100, n_features=4, noise=0.1, random_state=42)
16
17# Split the data
18X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
19
20# Set the experiment name
21mlflow.set_experiment("ML Model Experiment")
22
23def log_model(model, model_name):
24 with mlflow.start_run(run_name=model_name):
25 # Train the model
26 model.fit(X_train, y_train)
27
28 # Make predictions
29 y_pred = model.predict(X_test)
30
31 # Calculate metrics
32 mse = mean_squared_error(y_test, y_pred)
33 rmse = np.sqrt(mse)
34 mae = mean_absolute_error(y_test, y_pred)
35 r2 = r2_score(y_test, y_pred)
36 evs = explained_variance_score(y_test, y_pred)
37
38 # Log metrics
39 mlflow.log_metric("mse", mse)
40 mlflow.log_metric("rmse", rmse)
41 mlflow.log_metric("mae", mae)
42 mlflow.log_metric("r2", r2)
43 mlflow.log_metric("explained_variance", evs)
44
45 # Log model
46 mlflow.sklearn.log_model(model, model_name)
47
48 print(f"{model_name} - MSE: {mse}, RMSE: {rmse}, MAE: {mae}, R2: {r2}, Explained Variance: {evs}")
49
50# Linear Regression Model
51linear_model = LinearRegression()
52log_model(linear_model, "Linear Regression")
53
54# Decision Tree Regressor Model
55tree_model = DecisionTreeRegressor()
56log_model(tree_model, "Decision Tree Regressor")
57
58# Random Forest Regressor Model
59forest_model = RandomForestRegressor()
60log_model(forest_model, "Random Forest Regressor")
61
62print("Experiment completed! Check the MLflow server for details.")
ML Model Experiment -
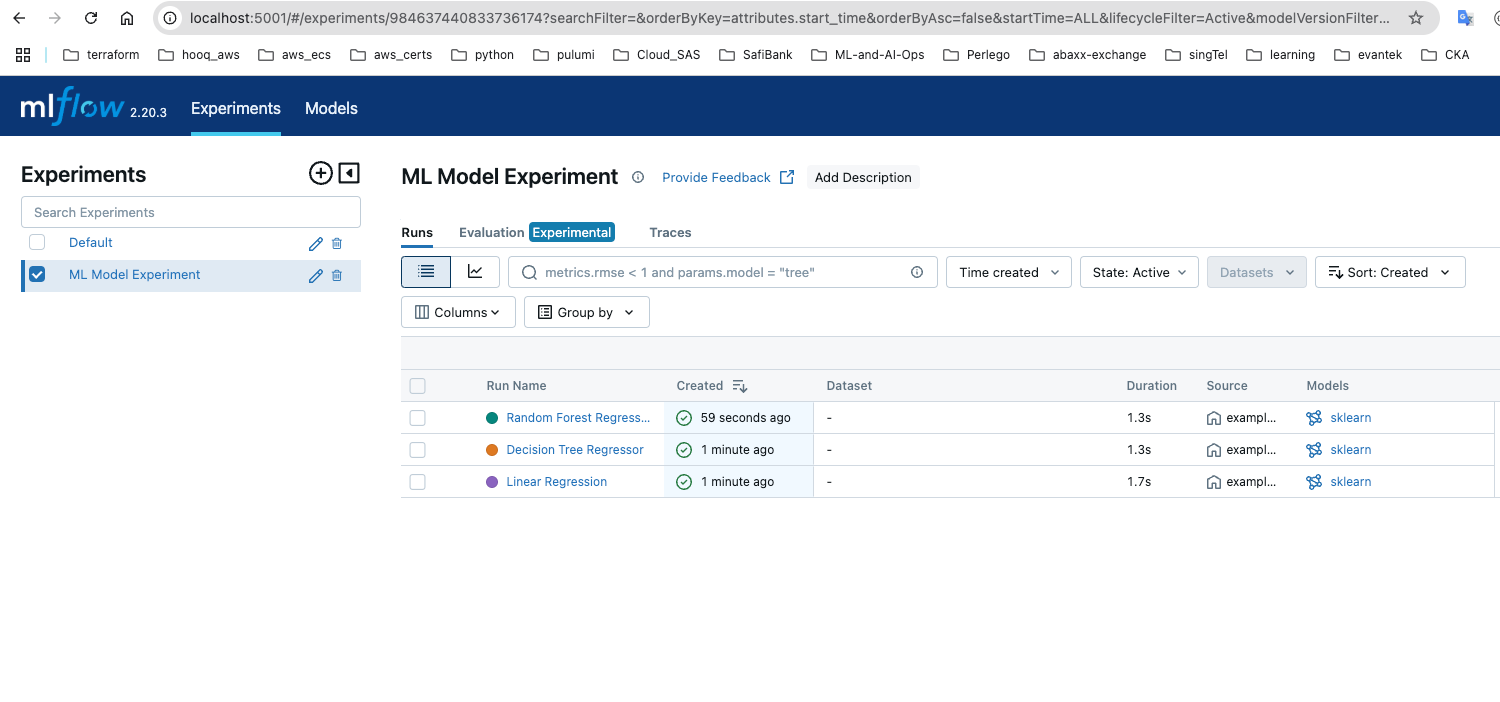
Run ML Model Experiment -
Experiments in MLflow
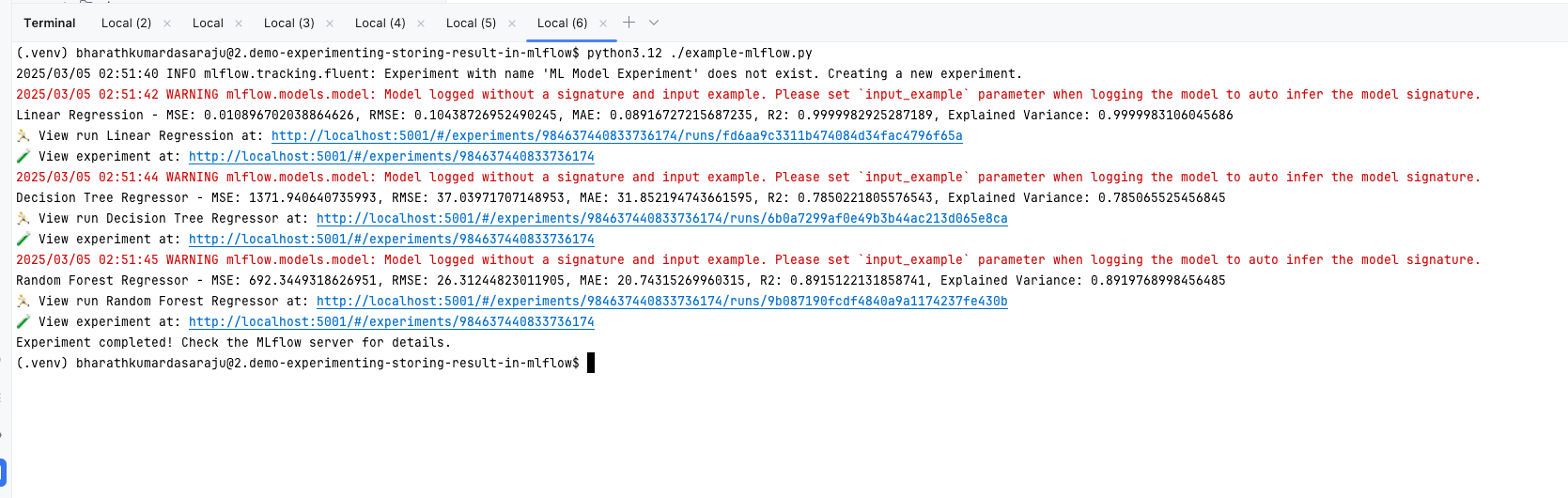
1Run the experiments locally and store the results in mlflow service.
2
3using scikit-learn to train mlmodel...
4mlflow
5scikit-learn
6
7datascience package scikit-learn
8
9so when the example-mlflow.py runs means when the model gets trained it stores all the results in remote mlflow server.
10
11
12ML model:
13
141. Train a model
152. Make some Predictions
163. Calculate metrics
174. Log metrics
185. Log model
19
20Now important part of run multiple models on the same data
211. Linear Regression Model
222. Decision Tree Regressor Model
233. Random Forest Regressor Model
24
25And we are storing all of the metrics generated by these models in our experiment.
26
27So we have one experiment with three model metrics.
28
29Since i run mlflow on the port 5001 .. update this code mlflow.set_tracking_uri("http://localhost:5001")
30
31(.venv) bharathkumardasaraju@4.Mode-Development-and-Training$ mlflow ui --port 5001
32[2025-03-04 21:05:55 +0800] [94896] [INFO] Starting gunicorn 23.0.0
33[2025-03-04 21:05:55 +0800] [94896] [INFO] Listening at: http://127.0.0.1:5001 (94896)
34[2025-03-04 21:05:55 +0800] [94896] [INFO] Using worker: sync
35[2025-03-04 21:05:55 +0800] [94897] [INFO] Booting worker with pid: 94897
36[2025-03-04 21:05:55 +0800] [94898] [INFO] Booting worker with pid: 94898
37[2025-03-04 21:05:55 +0800] [94899] [INFO] Booting worker with pid: 94899
38[2025-03-04 21:05:55 +0800] [94900] [INFO] Booting worker with pid: 94900
39
40
41
42(.venv) bharathkumardasaraju@2.demo-experimenting-storing-result-in-mlflow$ python3.12 ./example-mlflow.py
432025/03/05 02:51:40 INFO mlflow.tracking.fluent: Experiment with name 'ML Model Experiment' does not exist. Creating a new experiment.
442025/03/05 02:51:42 WARNING mlflow.models.model: Model logged without a signature and input example. Please set `input_example` parameter when logging the model to auto infer the model signature.
45Linear Regression - MSE: 0.010896702038864626, RMSE: 0.10438726952490245, MAE: 0.08916727215687235, R2: 0.9999982925287189, Explained Variance: 0.9999983106045686
46🏃 View run Linear Regression at: http://localhost:5001/#/experiments/984637440833736174/runs/fd6aa9c3311b474084d34fac4796f65a
47🧪 View experiment at: http://localhost:5001/#/experiments/984637440833736174
482025/03/05 02:51:44 WARNING mlflow.models.model: Model logged without a signature and input example. Please set `input_example` parameter when logging the model to auto infer the model signature.
49Decision Tree Regressor - MSE: 1371.940640735993, RMSE: 37.03971707148953, MAE: 31.852194743661595, R2: 0.7850221805576543, Explained Variance: 0.785065525456845
50🏃 View run Decision Tree Regressor at: http://localhost:5001/#/experiments/984637440833736174/runs/6b0a7299af0e49b3b44ac213d065e8ca
51🧪 View experiment at: http://localhost:5001/#/experiments/984637440833736174
522025/03/05 02:51:45 WARNING mlflow.models.model: Model logged without a signature and input example. Please set `input_example` parameter when logging the model to auto infer the model signature.
53Random Forest Regressor - MSE: 692.3449318626951, RMSE: 26.31244823011905, MAE: 20.74315269960315, R2: 0.8915122131858741, Explained Variance: 0.8919768998456485
54🏃 View run Random Forest Regressor at: http://localhost:5001/#/experiments/984637440833736174/runs/9b087190fcdf4840a9a1174237fe430b
55🧪 View experiment at: http://localhost:5001/#/experiments/984637440833736174
56Experiment completed! Check the MLflow server for details.
57(.venv) bharathkumardasaraju@2.demo-experimenting-storing-result-in-mlflow$
Evaluate ML Models -
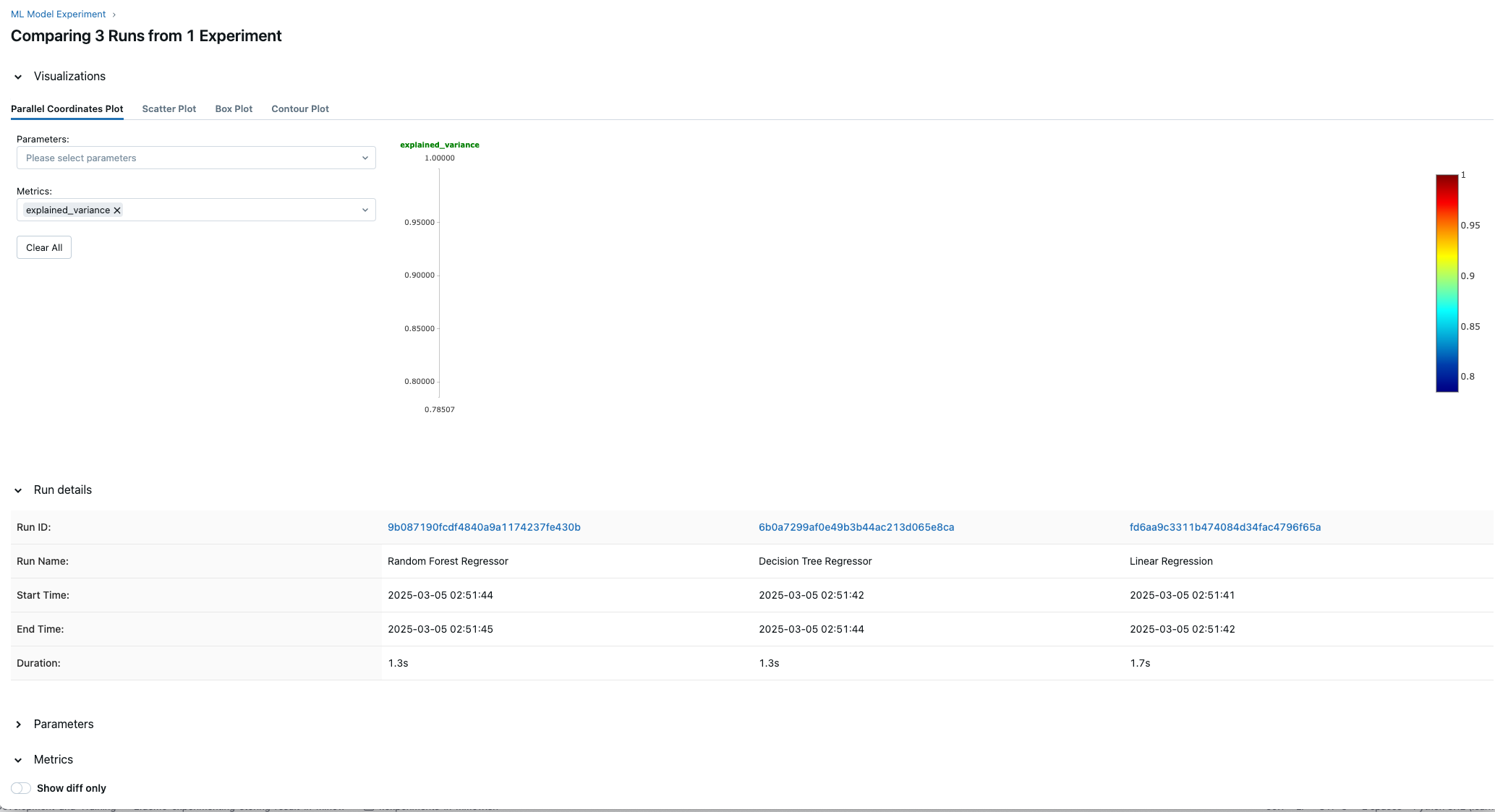
Compare ML Model Runs -
Model Artifacts -
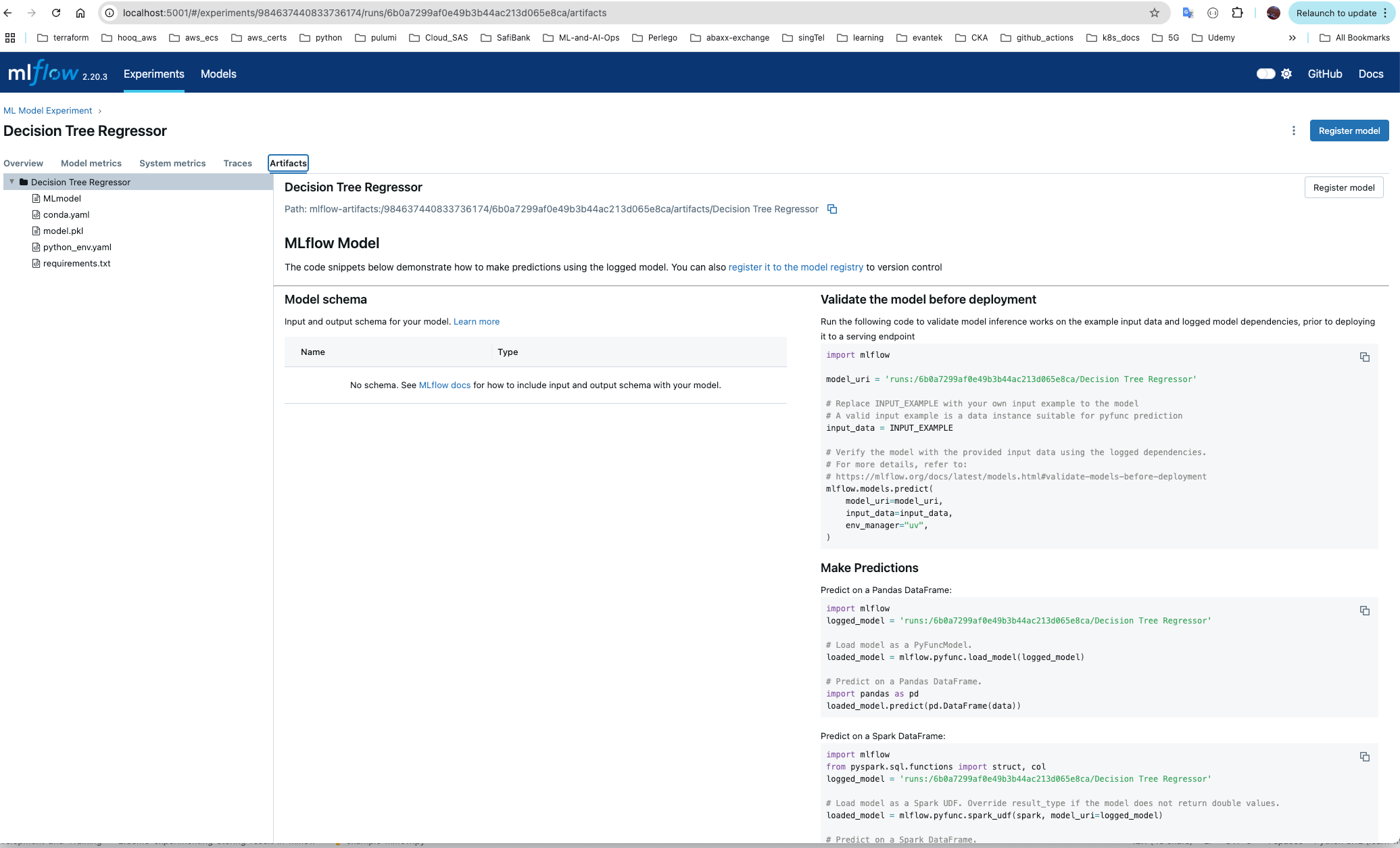
Store Model in Registry
1mlflow model artifact and versioning
2
3so if we choose in our experiment to go-ahead with the Decision-Tree Regressor model...
4So now we need select that models artifacts and store it in Model Registry, basically the model.pkl file for the Decision Tree Regressor Model.
5
6So when we deploying the model ...means serving the model.pkl in the API .. treat it like a jar or pypi package.
New ML Deployment -
Open Model File
1import pickle
2
3with open("model.pkl", "rb") as file:
4 model = pickle.load(file)
5
6print("model name is", model)
7print("model params are", model.get_params())
8
9
10if hasattr(model, "feature_importances_"):
11 print("Feature Importances:", model.feature_importances_)
12
13
Open Model File v1
1import pickle
2import json
3
4with open("model.pkl", "rb") as file:
5 model = pickle.load(file)
6
7print("\n📌 Model Name:", model.__class__.__name__)
8print("\n🔧 Model Parameters:")
9print(json.dumps(model.get_params(), indent=4))
10
11if hasattr(model, "feature_importances_"):
12 print("\n📊 Feature Importances:")
13 for idx, importance in enumerate(model.feature_importances_):
14 print(f" Feature {idx}: {importance:.4f}")
Data Handling in MLflow
1Grid Search technique used for optimizing hyperparameters in the training process
2
3below two metrics should be monitored to ensure that a model is balanced between precision and recall
4
5Precision and recall assess how well the model balances capturing relevant instances and minimizing false positives.
6True Positive Rate (Recall) and False Negative Rate (inversely related to precision) help monitor model performance.
7
8
9
10After training a model, the precision is high, but recall is low. Which adjustment should be made to improve recall?
11Lowering the threshold increases the number of true positives, thereby improving recall.
MLflow Runs Directory
`mlruns/`_ – MLflow runs directory in MLflow Example
Supporting Folders
mlruns/ (root) – MLflow runs directory
mlruns/ (example) – MLflow run directory used in specific example
mlartifacts/ – MLflow model artifacts directory